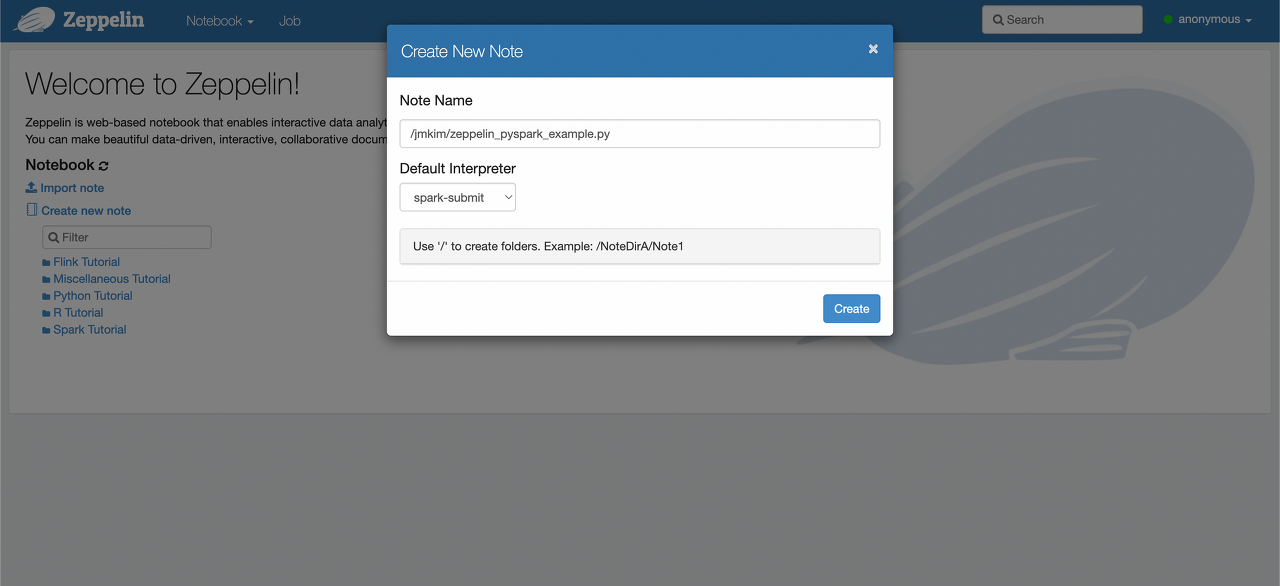
1. Create new note
- Zeppelin 홈 화면에서 “Create new note” 클릭 후 Note Name을 입력한다.
- Default Interpreter를 “spark-submit”으로 설정한다.
2. Zeppelin note 실행
- 셀의 우측위에 삼각형으로 셀단위로 실행하고, pending 상태가 finished 까지 기다린다. cluster mode 이므로 분산처리하기 위한 셋업시간이 기본적으로 걸림.(10초 이상)
%spark.pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
sc = SparkSession.builder\
.master("yarn")\
.appName("학번 Test")\
.getOrCreate()
df = sc.read.csv("hdfs:///test/KC_KOBIS_BOX_OFFIC_MOVIE_INFO_202105.csv", header=True)
df.select(col("MOVIE_NM"), col("MNG_NM"), col("IMPORT_CMPNY_NM"), col("GRAD_NM")).show()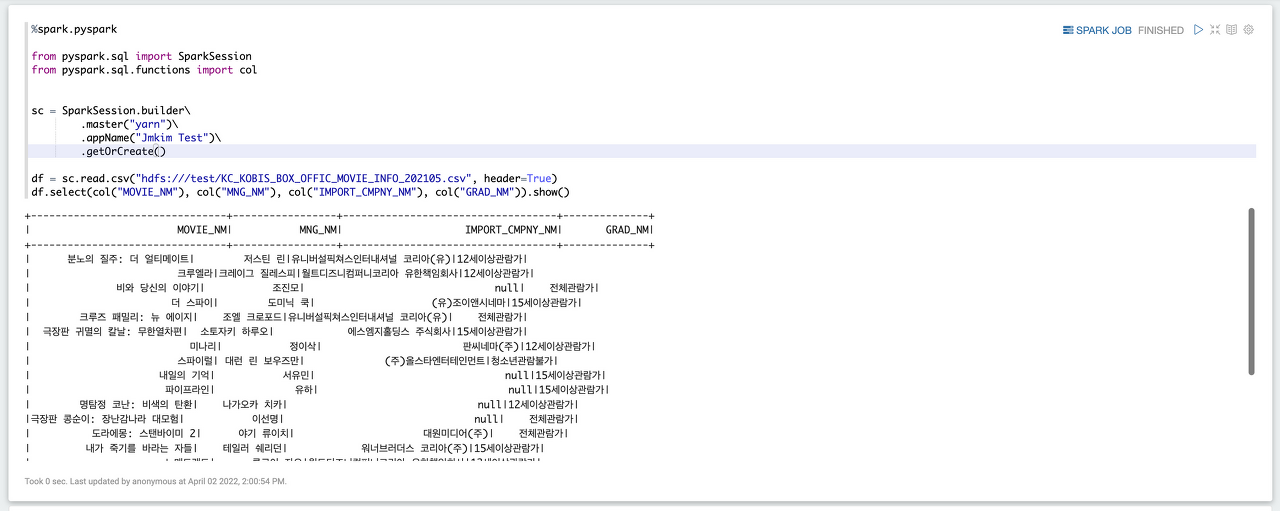
%spark.pyspark
df.printSchema()
%spark.pyspark
df.createOrReplaceTempView("movie")
%spark.sql
select MOVIE_NM, MNG_NM, DISTB_CMPNY_NM, OPEN_DE, GENRE_NM, GRAD_NM from movie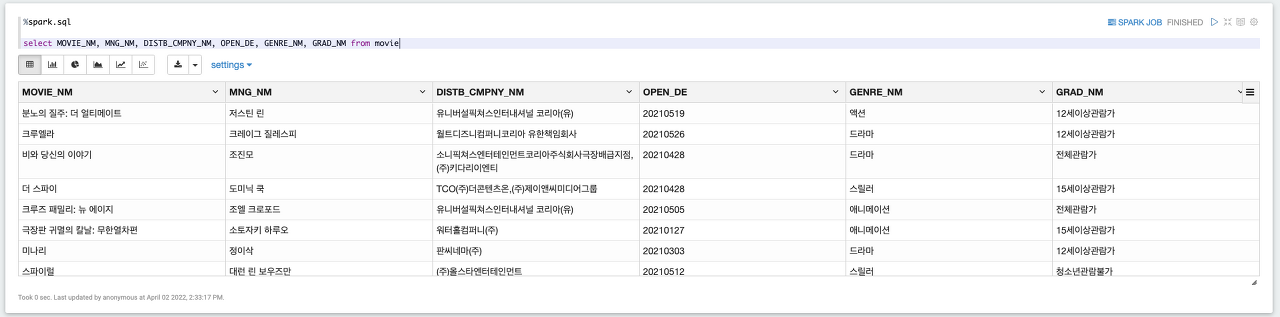
%spark.sql
select NLTY_NM, count(*) from movie group by NLTY_NM
3. Zeppelin 종료
/usr/local/zeppelin/bin/zeppelin-daemon.sh stop'빅데이터 분석 환경 구축' 카테고리의 다른 글
| Ubuntu 20.04 YUM Install (0) | 2022.11.28 |
|---|---|
| Trouble Shooting (0) | 2022.04.25 |
| 14. Zeppelin 설치 및 PySpark 연동 (0) | 2022.04.25 |
| 13. 클러스터 실행 스크립트 생성 (0) | 2022.04.25 |
| 12. Hadoop FailOver 테스트 (0) | 2022.04.25 |
