- 각 서버에서 Hadoop, Yarn 클러스터 설정 및 실행 테스트 한다.
1. NameNode 초기화 (nn1만!)
# hdfs namenode 포맷
hdfs namenode -format
2. NameNode 실행 (nn1만!)
# hdfs namenode 실행
hdfs --daemon start namenode
3. Standby NameNode 실행 (nn2만!)
# hdfs standby namenode 실행
ssh nn2
hdfs namenode -bootstrapStandby
4. start-dfs.sh 실행 (nn1만!) [Hadoop 실행]
- “DFSZKFailoverController” 프로세스가 실행 된다.
start-dfs.sh
# 확인
jps
5. start-yarn.sh 실행 (nn1만!) [Yarn 실행]
- “ResourceManager” 프로세스가 실행된다.
- 나머지 DataNode 서버에서는 “NodeManager” 프로세스가 실행된다.
start-yarn.sh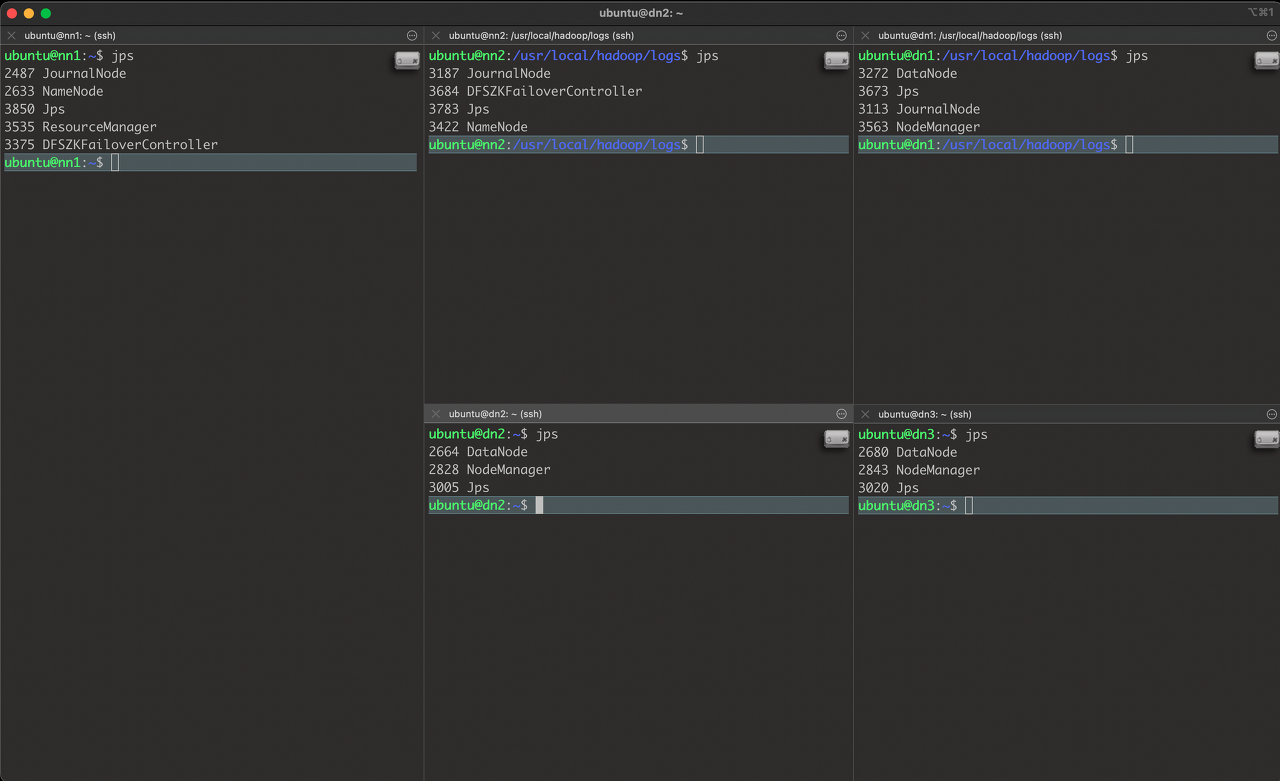
6. historyserver 실행 (nn1만!)
- “JobHistoryServer” 프로세스가 실행된다.
mapred --daemon start historyserver
7. Active, Standby NameNode 확인
hdfs haadmin -getServiceState namenode1
hdfs haadmin -getServiceState namenode2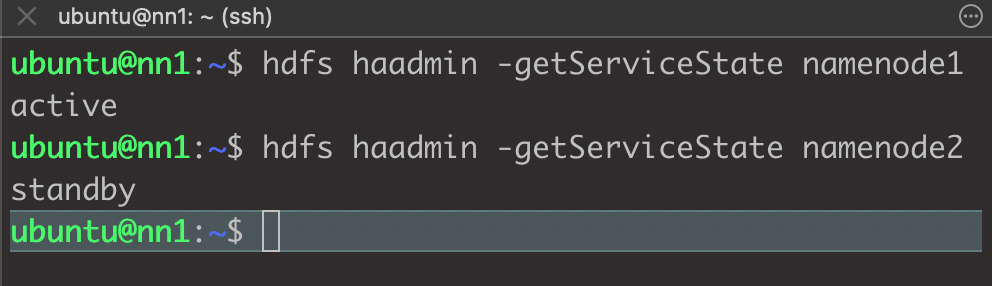
Hadoop Word Count 예제 테스트
- nn1에서 실행
# HDFS test 디렉토리 생성
hdfs dfs -mkdir /test
# HDFS LICENSE.txt 파일을 test 디렉토리에 삽입
hdfs dfs -put /usr/local/hadoop/LICENSE.txt /test/
# Word Count 예제 실행
yarn jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount hdfs:///test/LICENSE.txt /test/output
# Worn Count 결과 확인
hdfs dfs -text /test/output/*
'빅데이터 분석 환경 구축' 카테고리의 다른 글
| 11. 보안그룹 편집 및 WEB UI 확인 (0) | 2022.04.25 |
|---|---|
| 10. Spark 클러스터 실행 및 PySpark 예제 실행 (0) | 2022.04.25 |
| 08. Zookeeper 클러스터 실행 (0) | 2022.04.25 |
| 07. ssh에서 ssh 접속 (0) | 2022.04.25 |
| 06. AMI 생성 및 인스턴스 복제 (0) | 2022.04.25 |

